「気象データアナリスト」擬きを実際にやってみた(Part3)
はじめに
こんにちは、hiroです。Part 1では、Pythonを使って雲海予報をやってみて、Part 2では、実際に予報結果が正しいかどうか竹田城跡に行って検証してみました。
今回はPart 3ということで、そのうちこのブログは動画にするので、その下書きの為のブログだと思ってもらえれば良いと思います。「雲海予報-行ってみた編-」は以下のように作りました。
Part 3では、本当にそのプログラミング結果が正しいものだったのか、信頼性について整理したいと思います。また、AIを使ったプログラミングについて詳しいところを追っていきたいと思います。
雲海予報Q&A
雲海予報について、AIでやってみたと言っても、ChatGPTは嘘をつくといった噂もありますし、中々その信憑性について期待しづらいですよね。
そこで、あいなびに出てくる「風くん」を登場させて、「風くん」のAI雲海予報に対する疑問点に「あいりす博士」が応えるという、対話形式で皆さんの疑問にお答えしていこうと思います。それでは、Let's Go!!!


Q1.風くん 「雲海予報にAIを使っているけど、AIなんて信頼できるの?」
A1.あいりす博士 「結局、雲海「予報」なので、結果の信頼性について100%言い切れるということはありません。「70%出現する可能性がある」など、結果は確率的な表現となります。天気予報は、現在も旧来から用いられている数値予報というスパコンを使って物理モデルにて計算したものを用いて予報されていますが、最新の研究結果では、AIモデルの方が天気予報の精度が良い上に、計算の為の資源をあまり用いなくて済み、高効率である、という結果も出ています。」
Q2.風くん 「AIの代表格としての、ChatGPTは嘘をつくとも聞いたことあるけど…?」
A2.あいりす博士 「AIも日進月歩なので、完全に信頼し切ることは出来ません。AIは現状「道具」なので、何をどう使って、何を信頼して判断するか、責任を取るのは人間の役割です。」
Q3.風くん 「雲海予報は、どの位信頼できるの?」
A3.あいりす博士 「AIの信頼精度の計算については、学術的に「正しい」と社会的に認められた手法によって行っています。その信頼精度について、数値的に計算するのが、今回雲海予報に使ったAIの役割の1つです。ただ、ここで一概にAIと呼ぶのも良くなくて、AIも人間や動物のように、色々な性格(モデル)があります。信頼精度を高めるために、適切なAIモデルを使って、良いように手なづけるのは、人間側の仕事です。」
Q4.風くん 「ぶっちゃけた話、AIを使って雲海予報するの意味あるんですか?(笑)人間でも出来そうですよね?」
A4.あいりす博士 「はい、それについては、AIを使って予報することが楽しいからやっているところはあります。(笑)未来予測が自分で出来ると楽しいですよね。また、人間でも出来そうだという話についてもその通りです。今回の雲海予報についても、編者(hiro)も科学的根拠をもとに行ってみて、「季節的に昼と夜の気温差が大きいし、湿度が大きく、風が弱いので、これは出そうだな?」とアタリを付けていたから遠征に踏み切ったし、AI予報をやってみたところがあります。ただ、感覚的なものに頼りがちな人間に対して、AIは品質管理されたアメダスデータを使って、予報精度という、客観的な指標を出してくれています。ここで、AIが出した予報結果には主観性が含まれないという特性があります。」
Q5.風くん 「AIってどう判断しているのか、判断根拠がブラックボックスだと聞いたことがありますが…」
A5.あいりす博士 「はい、AIは人間のように、因果関係を論理的に説明することが苦手です。しかし、このような表を出してくれるAIも登場していて、「AIが何のデータを以てして判断の根拠にしたか」について可視化してくれます。今回の場合、「humid21」つまり「前日の21時の湿度」が一番の根拠です。その次に、「wind21(前日の21時の風速)」「wind18(前日の18時の風速)」と続きます。」

Q6.風くん 「すごい!」
A6.あいりす博士 「ありがとうございます。AIを扱うプログラマーについて、「データサイエンティスト」という仕事があるのですが、格好良いお仕事ですよね。あなたも興味を持ったら、一緒にデータサイエンスやってみよう!」
詳しいプログラミング手順
前回、Part 1にてプログラミング手順を紹介しましたが、余りにも雑ということを自覚しているので、今回、もう少し丁寧に雲海予報プログラミングについて解説していきたいと思います。
⓪環境構築
これについては省略します、自分はVisual Studio CodeでAnacondaを使っています。(その方がcsvを一緒に扱えたりなど、使い勝手が良いので。)

①アメダスデータを取ってきて読み込む、データの整形
気象庁過去のデータからダウンロードしてきています。
ここで、雲海の出る基本条件として、放射冷却が起こり放射霧が出現する条件と同じで、◯湿度が高いこと ◯気温差が大きいこと ◯風が強くないこと の3条件があげられますが、基本そのデータを取ってきました。
date,temp12,temp15,temp18,temp21,temp_diff1218,
temp_diff1518,temp_diff1221,temp_diff1521,temp_diff1821,
wind12,wind15,wind18,wind21,sun12,sun15,sun18,sun21,
humid12,humid15,humid18,humid21,result
が今回のデータのラベルです。前日の気温、風、日照量、湿度について、12時、15時、18時、21時のもの、前日の気温差について、18時-12時、18時-15時、21時-12時、21時-15時、21時-18時のものを計算しています。気温差の計算については、Pandasを使うことが多いですが、今回はChatGPTを使って計算するコードを書いてもらいました。(初めは前日の最高気温-当日の最低気温temp_diff、当日の湿度humid03、当日の風速wind03の3要素で計算していましたが、あまり予報精度が上がらなかったので、特徴量を増やしました。)
また、最後に、朝来市が公表している雲海結果について、「出ない」を0とラベル付けし、また、「うっすら、雲海、最高の雲海」を1とラベル付けしました。(初めは0,1,2,3の4段階でラベルづけしていましたが、予報精度が頭打ちになってしまったので、そもそもの判定としての判定数を減らしました。)
期間については、湿度の要素がかなり大切になると考えました。2022/10/26から和田山アメダスが更新され、湿度計が導入された結果気象庁HPのデータベースに湿度の値が格納されていたので、そこから2024年までのデータをAIに読ませることとしました。

②AIに計算させる
結局みなさんここが知りたいですよね??AIについて、多少知ってる人向けの説明としますが、今回使ったのは「教師あり学習」です。AIが
(a)「date,temp12,temp15,temp18,temp21,temp_diff1218,
temp_diff1518,temp_diff1221,temp_diff1521,temp_diff1821,
wind12,wind15,wind18,wind21,sun12,sun15,sun18,sun21,
humid12,humid15,humid18,humid21」
と
(b)「result」
の対応結果について、大体(a)がこんな時は(b)の0または1の結果になるなあ、というのを学習して、モデル(計算式や関数のようなもの)を作成します。
そして、そのモデルに対して結果を予測したい日の(a)のデータを読み込ませて、当日(b)の結果がどうなるかを予測させるというものです。
そして、その学習がうまく行っているかを見るのが、「Accuracy」(予測精度)と、「Loss」(損失関数)です。AIのモデル作成が上手くいっているかどうかを可視化するために、最終的に作成するのは以下のようなものとなります。

「iteration」が横軸にありますが、何回か同じデータについてモデルを作り直すという過程を踏んで、より予測精度の高いモデルを作成しています。
trainデータ(訓練データ。統計的手法で元データを訓練させるデータとそのモデルの熟練度を検証するデータに分けて、性能を評価しています。この手法をcross-validationと言います。)とtestデータ(テストデータ。熟練度を検証するデータ)について、青とオレンジでモデルを熟練させている様子が可視化されています。最終的に、trainは9割弱精度が出ていますが、testは6割強出ていますね。つまり、この雲海予報モデルは6割強の精度を出せるということです。
また、その右にあるのが、損失関数のデータです。損失関数についての詳しい説明は省きますが、AIがモデルを作るにあたって、そのモデルが安定した結果を出してくれるかどうかを評価する指標のようなものです。損失関数が低い位置で収束してくれると、「そのモデルは安定している」と言うことが出来ます。今回はtrainが青色で収束しているのに対し、testはオレンジ色で少し上側に伸びていますが、最終的に下側に戻ってきて安定している様子を見ることが出来ます。

その結果を、記述形式で書かせたのが以上のものとなります。正解率は63%、損失関数は1.02、2024/11/09のアメダスデータを通したところ、「予報結果は、雲海は出る予報です。」と記述されていますね。
よって、①高い精度を出すモデルを作ること ②損失関数の低い安定したモデルを作ること
が目標となり、それをグラフで確認することが出来ます。

今回使用したモジュールは、numpy、pandas、matplotlib、scikitlearnです。scikitlearnはAIを使うためのモジュールの一つで、今回は雲海予報結果が離散値なので、回帰ではなく分類を使うということで、「MLPClassifier」を使用しました。

まず、先ほど整形したcsvファイルについて、pandasで読み込んでいますね。
その中で、余りにも0の値が多い「sun18」「sun21」は予測精度の為に計算させるデータには含めないこととし、また、「date」「result」については計算させる為には不要なので削りました。計算させるデータをXとして、結果の「result」をyとしています。
また、計算させるデータは、クロスバリデーションを用いてtrainデータとtestデータに分けた上で、正規化と標準化という統計的手法で、計算させやすく数値的に整形しました。

今回使ったAIは、MLPClassifierです。ここが一番要ですね。色々パラメータチューニング出来るので、頑張ります。
そして、正解率と損失関数について、MLPClassifierに付属している機能として計算しています。
最後に、2024/11/09の和田山のデータをAIに読ませることで、雲海が出るか出ないか、計算させています。

最後に、イテレーションしてモデルがどのように進化しているかについて可視化するために、もう一度MLPClassifierを回しています。イテレーション回数は今回は100回です。基本的に収束したらOKですね。一回一回正解率と損失関数について計算結果を配列に格納していき、最終的にグラフを出力しています。グラフの出力結果をもとにフィードバックを効かせて、MLPClassifierのパラメータ、特徴量の数など、様々なパラメータをチューニングしていく、というのがAIの精度を向上させる為に行うこととなります。
おわりに
如何だったでしょうか。AIの信頼性について、ご確認いただけましたか?どのデータを使うのか、どのAIモデルを使うのか、など、データサイエンスを行う上で考えることはたくさんあります。また、計算量が今回は少なかったから良かったですけど、計算量が多くなるとそれなりにPC側のスペックを高くしないといけなくて、出来るだけ計算量を少なくしたアルゴリズムを考えたり、PC側の性能を上げるべくハードを整備したりすることもあります。
中々世間一般に浸透していないデータサイエンティストですが、これを機会に、少し勉強してみませんか??
「気象データアナリスト」擬きを実際にやってみた(Part 2)


はじめに
こんにちは、hiroです。前回、このブログではニューラルネットワークを使って雲海予報をやってみましたが、今回はその実践編というか、実際に予報結果が正しいかどうか竹田城跡に行って検証してみたのブログとなります。僕のブログでは珍しくゆるい話なので、ゆるりと読んでいただけると思います。
大阪駅から竹田城跡のある兵庫県北部へ!




住んでいるマンションから、大阪駅へと向かいました。大阪駅昼前着位かな?特急券を買って、和田山駅へと向かうための手配をしました。ここで、兵庫北部に向かう為には姫路経由の南回り「はまかぜ」と福知山経由の北回り「こうのとり」「きのさき」があったのですが、自分は艦これの「浜風」が好きなので、直感で「はまかぜ」を選んでしまいました。後で旅の同行人に聞くと、「はまかぜ」はディーゼルカーでエンジン音が変わっているらしいです。おお、流石鉄オタ。そういう旅の楽しみ方もあるのか。


12時23分発に乗るので、お昼ご飯を車内で食べようと、大阪駅で駅弁を購入しました。香住行きなので、蟹だろ!って事で「かにめしとすきやき弁当」をお買い上げです。味がしっかり染みてて、美味しかったです。これを食べ、兵庫県北部に行くという気持ちを新たにしました。ああ、城崎温泉行きたい、、、
和田山駅に到着!早速アメダスへGo!



2時間揺られ、和田山駅へ到着しました。「天空の城がある町 朝来市へようこそ」と書いてある看板を発見しました。天気は晴れ。晴れてくれた方が雲海を見る明日の気温との気温差が大きくなるので良いです。ホテルに行く前に、まずは和田山アメダスへと向かいます。田舎の自然に囲まれて、清々しい気持ちで散歩することが出来ました。ただ、ちょっと遠かったかな汗





多分40分強歩いて、和田山駅から和田山アメダスに到着しました。「和田山地域気象観測所」の看板がありますね。神戸地方気象台の皆さん、いつも点検お疲れ様です!!!
どう入るのかなあと思ったら、このアメダスは消防署の中にありました。「気象関係ではありますが、今回はプライベートでアメダスを見学したくて…」と許可を貰い、アメダスを見せてもらいました。あるのは、「雨量計」「通風筒(温度計・湿度計)」「風向風速計」「積雪計」ですかね。今回雲海予報に用いたデータは「湿度・気温差・風速」なので、その測器がちゃんと存在していることを確認できました。写真には載せていませんが、通風筒は3枚目の写真の柱の裏に、風向風速計は柱のてっぺんにありました。
どうアメダスデータを現地からネットや気象台まで送っているのか、通信システムにも興味がありますね。
ホテルへ


アメダス見学を終え、また50分弱位歩いてホテルへ向かいました。HOTEL VILLAGEという場所です。お値段は素泊まりで1泊6500円くらい。綺麗な場所でしたし、まあそんなもんでしょう。雲海を見に行くんだろうなと見られる親子連れなどが宿泊していました。一息ついた後、旅の同行人が和田山駅に到着したことを聞き、和田山駅周辺で晩御飯を食べました。その後、2人でホテルに戻ってきて、明日のシミュレーションをしました。
さあ、明日はいよいよ雲海を見に行きます。
2日目、竹田城跡までの道のり

竹田城跡に行くには、竹田駅からバスを使って途中まで登るか、40分登山して登るかの2通りの行き方があります。今回は、私がバスや鉄道が得意ではないのもあり、慣れたいということで、バスを使って登山することにしました。体力温存ルートですね。
取り敢えず6時過ぎの電車に乗らないといけないので、5時半起きの5時45分ホテル出発です。



道はまだまだ夜明け前で暗いですね。なんか霧が出てないか?上に登った時には、綺麗に見えるのかなあとか不安ながら、和田山駅に到着です。ここから、あいなびのまななさんに作ってもらった、「あいりすちゃんアクスタ」登場させます。(かわいい!)あいりすちゃんと一緒に雲海を見に行きます❣️




まずは播但線に乗って竹田駅に着きました。バスに乗って、頂上まで上がります。結構混んでましたね、、、竹田城跡への観覧券を買っていよいよ雲海を見に行きます。ここまでスムーズに来ているが、果たして雲海は見えるのか???
雲海見えた!!!


登っていく途中ではずっと霧に囲まれていましたが、最後の最後で霧を抜けました。「おっ、晴れてる!!すご!!一面に雲海が広がってるやん!」の一言です。雲海見れて、あいりすちゃんも何となくご機嫌そう。この日の朝の気温は5°C位でしたかね。前日の最高気温が豊岡で20°C前後だったので、気温差は十分にあります。湿度も80-90%位あったと思います。風も弱かったです。ということで、雲海にはうってつけの条件でした。30分位眺めて、大喜びで帰路に着きました。
おわりに
今回は、私が後々データサイエンスを志していきたいという希望を胸に、一度データ分析がどんなものなのかっていうのを楽しみながら勉強してみました。雲海予報については、一応、高い値を出した時に行ってみると雲海が出た、という形になります。
学校で勉強した物理や数学は絶対的な答えがあるというか、正しいことが決まっていましたが、データサイエンスや統計は絶対的なものに決まらず、確率的な表現となります。天気予報のような未来の予測については、絶対的に正しいということは言えません。ただ、予想している段階では「ドキドキ・ワクワク」予想が当たったら「嬉しい!」予想が当たらなかったら、「何でそうなったんだろう?面白い!」そういう感情的なものを楽しめたのは確かです。
ただお金を稼ぐだけじゃなくて、データサイエンスを使って、自分も他人も一緒に楽しめるような、そんな生き方をしていきたいなあと漫然と考えています。
「気象データアナリスト」擬きを実際にやってみた
はじめに
お久しぶりです、hiroです。私はと言いますと、一年前からIRIS NAVIGATION(通称あいなび)というYoutubeグループを立ち上げてそれに参加していて、現在も気象予報士試験に関する解説動画を作成しています。
Xでは気象予報士試験の仲間とワイワイ盛り上がっていますが、試験に合格した人も沢山出てきて、実際、気象キャスターとして活動したり気象会社で働いたりして、資格を活用している人も居ますが、気象予報士という資格の性質上、折角身につけた気象の知識を活かせなくて困っている人も多いように見受けられます。
そこで、昨今のAIの勃興と合わせて、「気象データアナリスト」に着眼した方も多いのではないでしょうか。しかし、どの人もまずその知識を身につける為の養成講座を見て驚くのが…

は?!100万弱するやんけ!気象予報士が資格取得条件無いし、ネット上に解説記事も多く上がっていて、金銭的な障壁はかなり低かった故に、この金額には狼狽する方が多いと思います。
そこで思ったのが、、、ちょっとどんな感じなのか中身を覗いてみたい方の為に、ザッとどんなことをやるのか、大学でプログラミングを勉強して、多少AIの理論的な勉強をしたりAIを触ったりしたことがある私がお見せ出来たら面白いんじゃね?!と思ったのでやってみたいと思います。あくまでも想像の範囲内ですが。
気象データアナリストって何するの?!
ということで、まずは講座内容を見てみました。

ふーん、雲海。面白そうやん。この講座では秩父山地の雲海を題材にデータサイエンスを行うようです。雲海予報とかするんかなあ。

ふむ、雲海発生記録データとアメダス秩父の特地の気象観測データを利用するらしい。そらまずは雲海予報するんやろなあ。

中々応用するのは難しそう、、、ただ、データサイエンスを商業利用するんだろうってことは何となく「講座が目指すゴール」からは分かるね。
雲海予報の計画
取り敢えず、気象データアナリスト養成講座の講座内容に従って、雲海予報をやってみたいと思います。
Google検索したら、出てきたわ、雲海予報実際にやってみてる人。
記事を見てみると、なるほど、アメダスデータはTellusという衛星データプラットフォームから取ってきてるようですが、そんなことしなくても気象庁HPの「過去の気象データ」からデータは取ってこれるよな?

また、言語はPythonなので自分は使ったことがあるし、この記事レベルのことをするのならそんなに障壁は低くなさそうだ。
この記事では講座でも紹介されている秩父の雲海予報をしているようですが、自分は現在関西住みなので、兵庫の「竹田城」の雲海予報をしよう!と思い至りました。
竹田城の雲海予報
よし、なら善は急げということで竹田城の雲海予報やってみようじゃないか。
予報の手順としては、
⓪Pythonの環境構築
①アメダスデータを取ってきて読み込む
②データの整形
③AIにデータを読み込ませる
位でしょうか。プログラミング初心者向けに丁寧に手順を追っていこうと思いますので、分かっている方はある程度読み飛ばしてください。
⓪Pythonの環境構築
Pythonを扱う方法は色々ありますが、初心者向けに一番オススメするのが、「Anaconda」のインストールです。Anacondaは、データサイエンスや機械学習に関する作業を効率的に行うプラットフォームといった感じですね。
インストールの仕方については、ある程度ググってください。OSの種類に注意してください。そしてAnaconda Navigatorを開いてください。

その中の、今回はSpyderというアプリを使いたいと思います。Python専用の統合開発環境といった感じです。

これでPythonを扱う為の環境構築は完了です!
①アメダスデータを取ってきて読み込む
それでは、アメダスデータを取ってきて読み込んでみましょう。先ほどの気象庁HPの「過去の気象データ・ダウンロード」のページに進んで、アメダス和田山の気温、風向・風速、現地気圧、相対湿度にチェック入れて2023年9月1日から2023年11月30日までの時別値をCSVでダウンロードしました。その結果を私はVSCodeで開いています。ダウンロード結果を表示します。

こんな感じです!どうですか?
②データの整形
これについては、PythonのPandasというモジュールを使ったのですが、、、やってみた結果、とても面倒でした。エクセルの関数などを使って整形するのが良いと思います。(Pandasの扱いには慣れが必要みたいです。)

雲海予報には「湿度」「前日と当日の気温差」「風速」のデータが必要と分かったので、その「前日と当日の気温差」については「前日13時と当日3時の気温差」を計算し、「湿度」「風速」については当日朝3時のものを抽出しました。また、
以上のサイトより雲海の結果を数字で表示することにしました。以上のサイトの表記を使って、「0: 出てない 1:うっすら 2:雲海 3:最高の雲海」というナンバリングをしています。表の最後にこの雲海の結果は付け足しました。

最終的に、こんな感じになっています!!!
③AIにデータを読み込ませる
AIは今回、回帰式であるランダムフォレストを使ってみたいと思います。AIライブラリで有名なScikit-learnのRandomForestRegressorを使ってみることにしました。コードは、以下のような感じになっています。


ここで私は、Pandasの扱いに慣れていない為ChatGPTに頼ってコードを一部書いてもらいました。また、以下のサイトを参考に書いています。
それでは、実際に予報結果を出してみましょう、結果は???
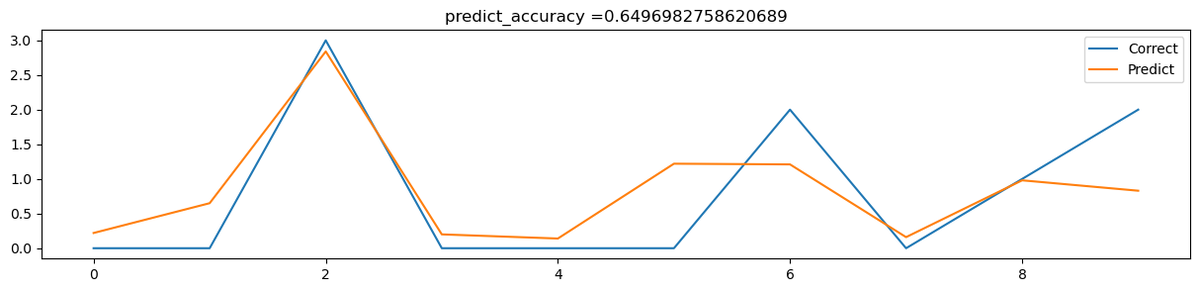
今回、機械学習を使うにあたって交差検証(cross-validation)を使っていますが、そこでtestデータを使っての予報結果が以上のグラフです。青色が正解データ、オレンジ色が予報データとなっています。これが重なるほど予報精度が高いということになります。
predict_accuracy = 0.6496982758620689なので、予報精度は65%程度と言ったところでしょうか。
おわりに
今回は、ランダムフォレストを使って「気象データアナリスト」擬きのデータサイエンスに挑戦してみました。
大体こんな感じ?っていうのを掴んでいただけたら幸いです。(繰り返しますが、あくまでも予測の範囲内ですが…)面白い!と思ったら今回の手順を追ってみて、皆さんも実際に雲海予報を試してみてください。
因みに、、、私は、この雲海予報を元に実際に雲海が出るか予報してみて、雲海を見てきたいと思っています!朝来市の詳細な天気予報について、tenki.jpが提供してくれているんですよね。その様子もブログに出来たらと思っていますので、ご期待ください笑
それでは!!!
なんでも勉強会まとめ

はじめに
気象予報士自習室Discordにて、個人的に勉強会を開いています。その名も、「なんでも勉強会」。気象予報士に関するものに限らず、様々な話題について知見を広げようという勉強会です。私は、この勉強会の主催者でもあるんですが、講演者でもあり、今までに6回の発表を終えました。
折角なので、発表したパワポについてブログにログとして残しておこうと思い筆を執った次第です。
資料紹介
2023/6/3 「不思議な世界へおいでませ?量子論の世界」
量子論.pdf from hiro150493
2023/4/29 「AIの中身を大解明?!ニューラルネットワークの説明」
2022/12/17 「世界一美しい数式 e^iπ + 1 = 0の世界」
数学.pptx from hiro150493
2022/7/10 「マリオカートを作ろう! -NAKASUKART-」
マリオカート紹介.pdf from hiro150493
2022/7/10 「車のエンジンを作ろう!」
車のエンジンの設計.pptx from hiro150493
2022/4/23 「航空宇宙工学科と宇宙イベント」
おわりに
Discord勉強会は滅茶苦茶面白いです。寒冷渦やアークといった気象ネタから、漢方、投資など、出てくる話題は様々です。
何でも検索したらヒットする世の中ではありますが、同じ目標(気象予報士試験)を目指している、または目指していた同士から、知見を頂戴出来るというのは、非常にありがたい機会なのではないかと思います。
講演者側としましても、知っていることを講義形式とすることで頭の中の整理に繋がりますし、何より人の役に立てて嬉しいです。
これからも、このDiscord勉強会のような勉強会は、形を変えながらも続いていってくれれば良いな、続かせていきたいなと思っております。
何を目指して生きるのか本気で考えてみた part4

はじめに
こんにちは、hiroです。社会人生活も2年目となり、組織の中での生活も慣れてきましたし、徐々にキャリアとしての目標も明確なものとなってきました。また、恋活婚活を進めることとなり、お付き合いにこそ至っておりませんが、「結婚」が目標として見え始めてきており、仕事面だけでなくプライベート面でも考えることが多くなってきました。前回このシリーズのブログを執筆してから、将来について、人生について、個人的に考えたことは多いので、思考を記録・整理しておこうと考え筆を執った次第です。
実際に社会人生活を進めたところでこのシリーズについて振り返ってみて、再び考え直したいことについて、一つ一つ熟考していきたいと思います。
「主体性」とは何か ~自分で自分を育てる~
私は、part3にて、「何を目指して生きていけば良いのか」という問いに対して、信念の醸成を行うのが大切であると述べ、それを行う為には、「愛する」ことだと考えました。しかし、私は、この内発的動機づけに基づいて「愛する」ことの方法がよくわからない、だからこそ信念を育てられないのだと述べました。
「愛する」こととは、主体的に選び取ることであり、主体的に選び取ることこそ、内発的動機づけを根源にしていると考えます。しかし、他者に評価されることを主の目標として受け身的に生きてきた私には、この内発的動機づけの制御の仕方がよく分からなかったのです。
私は、この主体性の考察を暫く放置していたのですが、ある時、職場の同期にも、高校同期にも、「君には主体性が足りない」と指摘されてしまいました。社会生活を行う上で、主体性は、組織や社会をより向上させることに繋がる為、殆どの場合プラス評価に繋がります。
そういった社会生活を行う上での背景もあり、私は「主体性」の考察に取り組むこととしました。
結論から言うと、「主体性」を考えるにあたって重要な要素だと思ったのは、「好奇心」です。私には、好奇心が足りない。それは大学時代から薄々感じていました。受け身的に他者評価を目指して生きていた大学時代の私は、レポートや論文を仕上げる過程で、どうにも中途半端なところで満足してしまうのです。何かを深めようという貪欲な姿勢が無い。貪欲に物事を進められる姿勢こそ、好奇心の賜物であり、それが主体性に繋がると考えました。
そこで、私は、「好奇心」について、心理学ではどのような記述が為されているかについて調べてみました。
「好奇心」には3種類あるとのことでした。「拡散的好奇心」「知的好奇心」「共感的好奇心」の3つです。拡散的好奇心とは、人間が目新しいものに惹きつけられる時の心の動きのことであり、他2つの礎となるものであるらしいです。また、拡散的好奇心を発展させる為には、学ぼうとする努力によって好奇心に方向を持たせることが必要になるとのことでした。つまり、好奇心を伸ばす努力を行わないと、何の洞察も得られないまま終わってしまうということです。つまり、「愛せない」。これは私にとって致命的なことです。
「知的好奇心」とは、拡散的好奇心を能動的に方向づけた結果、知識と理解を求める意欲が内面から湧き上がってきたときのそれです。知的好奇心によって創造力、独創性、問題解決などの才能が高まり、イノベーションが生まれる契機が作られ、継続的な満足感や喜びが得られるようになります。私のこれまでのブログを読んでくださった方なら憶測されると思うのですが、これはpart2で述べた「知的好奇心を重要視していきたい」ですし、それ自体「愛する」ということです。
「共感的好奇心」とは、拡散的好奇心を能動的に方向づけた結果、他人の考えや感情を知りたいという意欲が内面から湧き上がってきたときのそれです。共感的好奇心によって、「なぜ好きなのか」「なぜこのような言動をするのか」「なぜこの仕事を選んだのか」といった、その人がこのような結論に至った理由を考えて理解し、他人に寄り添うことが出来ます。これはpart1で述べた「幸福なコミュニケーション」であり、「コミュニケーションを重要視していきたい」ですし、それ自体紛うことなき「愛する」ということですよね。
この「知的好奇心」「共感的好奇心」はお互いがお互いを高めあうらしいです。また、2つのバランスを取ることが大切であるということを書いてありました。
つまり、「主体性」とは好奇心の賜物であり、それ自体が「愛する」ということ、すなわち「幸福になる」ということなのです。私は、これらを頭の中で整理し終わった後、衝撃を受けました。世の中はこうやって幸福になれる仕組みになっているのか、と笑。つまり、ポジティブに捉えると、私は職場の同期や高校同期に、「もっと幸福に主体的になれよ!」とエールを送られていた訳です。私は、幸福になることの芽を自ら摘み取っていた、というか、そもそも幸福になるという目的に対して、その方法が分からなかったし、その方法で合っているという確証が得られていなかったということになります。
好奇心を育てるということが「自分で自分を育てる」ということであり、幸福になるための手段だったのです。好奇心を育てる為の支柱が「信念」という論理であり、信念を育てる為には、内発的動機づけとしての、拡散的好奇心を大切にすることが大切であると。
しかし待て、「信念」は何処を向いて育てれば良いのだ?そして、「愛する」為の技術的方法とは?
これは、今までのブログである程度答えが出ています。信念は、「組織」「社会」に向けば良いのです。「愛する」為の技術的方法とは、主体的な態度で、自分自身が自由を謳歌しながら、組織・社会が動く・回ることを確認し、それを楽しむことだと考えます。幸福とは「愛する」ことであり、好奇心を努力によって育てて、主体性を発揮し、組織・社会を動かすことです。その為には、「知的好奇心」「共感的好奇心」のバランスを自分の中で取る必要がある。
おわりに
皆さんはここまで読んですっきりしていただけたでしょうか。私は「幸福」「人生」について、今まで考えてきたことが一つになって満足しました。ただ、私はまだこの「愛する」ということの具体的方法を知らない。抽象的に論理構造を整えただけであり、根茎葉がどのように伸びていくのか、分からない。この「愛する」ということ、心と頭を総動員して、「知」「配慮」「尊重」しながら、他者や組織について「責任」を負う過程を楽しむ中で、自分と他者の成長を見守ることについて、まだまだこれから沢山の新しい気付きに出会えそうです。また何か気づきがあれば筆を執ります。
何を目指して生きるのか本気で考えてみた part3

はじめに
前回の記事で少しTwitterで反応があった「何を目指して生きるのか」シリーズです。ちょっと考えた結果、part1での自分の「努力」に対する根本的な考え方がpart2での「信念」の醸成を阻害していると思い至ったので、筆を執りました。果たしてどういうことなのか、そして「信念」はどのようにすれば醸成されていくのか、私なりの考えを纏めたいと思います。
間違っていたかもしれない私の中の「原理」
まず、私の中の原理として、現状に甘んじてはいけないというのが第一原則です。「何らかの努力をしている自分」が前提に来ます。自分の中で最大限の努力をすることで、例え良い結果が出なくても、その努力の過程を楽しめれば良いだろう、というのが私の中での一番です。
これは私がpart1で一番初めに書いた私の「原則」です。皆さんには「まあそういうものだ」ということで読み飛ばしていただいた部分ではないかと思うのですが、これがpart2で述べた私の「信念」の醸成を阻害していると思い至りました。
どういうことかというと、この原則は「成果主義」に則っているということです。
努力をしている自分や、努力の過程を好きになることで得られるメリットとしては、「高い順位が付けられたり、褒賞が与えられたりすることが価値基準となる場」に於いて、絶大なメリットがあります。
当たり前ですが、勉強をすれば成績は上がります。筋トレをすれば、筋肉が身に付きます。このように、沢山の結果が結びつくこととなり、努力を好きになることで得られるメリットは計り知れないです。また、努力を好きになることで、忍耐力も身に付きます。例え失敗したとしても再び立ち直ることが出来ます。また、例えしんどかったとしてもそれに耐えて、再び努力の場へと向かうことが出来ます。このように、努力を好きになることは、努力し結果を出し、他者に認められる存在となる上で、心理的に最適な道のりとなる訳です。実際、他者から課題を与えられる学校という場で結果を出す為には、「素直に全てを受け容れ、それらのものを好きになる」というマインドセットが最適になることは私のこれまでの経験からほぼ確証を持って言うことが出来ます。私自身、東京大学に合格しましたし、スポーツもある程度大体できますし、努力に関してはセミプロです。
ただ、その「努力そのものが一番であり、努力を好きになる」姿勢は、外から与えられることが前提になっています。また、目指すところが、最終的に「他者から評価される」ことに落ち着いてしまいます。いや、これは全然モチベーションとして良いし、それで社会適応してこれたのだから問題ないのですが、こと「幸福」軸が噛んでくると話が少し違ってきます。私は、part1で「愛する」「愛し合う」ことが幸福であると述べました。この「愛する」という動作には、「能動的に選び取る」という要素が入ります。しかし私は、現在のままのマインドセットでは、「他者から愛される為に愛する」というところに落ち着いてしまうのです。これは能動的・主体的ではありません。受け身の姿勢です。私が「愛する」為には、「愛される」を目指すことが前提条件になっている。これは心理学や教育学でいうところの、外発的動機付けによる行動でしかないです。これは幸福なのかというと、私はそうではないと考えます。
勿論、どうにもならないことは社会生活を行う上で沢山あります。その中で、「努力を好きになる」姿勢は高度に最適な社会適応であると言うことが出来ると思います。が、主体的に選び取っていくことを自分に許しても良いのではないか?という提案を自分は自分に投げかけたいです。好きなものにもっと正直になって、研究し、配慮し、愛でて、人生を充実させていっても良いのではないでしょうか。外発的なものに囚われ、内発的な自分の声を無視していることが、私の「原則」の欠点ではないかと、そう思い至った訳です。これは、少し誇張して言えば、社会がそう促すならば、世界が破滅していくような方向へと向かう努力についても容認してしまう、ということになります。
私は、自分の感情に基づいて、このような能動的であり、主体的であり、我儘ともいえるような、「愛する」行為を自分に促す方法を知りません。「愛する」ことは水をやり、成長を積極的に気にかけることです。「愛する」ことで、愛された側だけでなく、愛した側も成長していくことが出来ます。「愛する」対象は、人に留まりません。森羅万象全てを愛することが出来ます。私は、事物を「愛する」ことで「信念」が形成されれいくのだと考えます。それも、内発的な動機で「愛した」からこそ自分の中に揺るぎのない「信念」が醸成されるのだと考えます。だから、私は「信念」を醸成していけないし、「信念」を育てていく方法が分からないのです。
Part2で、「知的好奇心を尊重していきたい」「信念を醸成したい」という2つのキーワードについて言及しましたが、これらは密接に関係しあっていると考えます。自分の知的好奇心を尊重した行動を自分で選び取っていくからこそ信念が醸成されていくのです。
また、part1での「幸福なコミュニケーション」も信念の醸成に関わります。ただ、目的が何処にあるか、については、自分以外の場所にあるのではなく、自分の中にある、ということを補足したいです。自分の内発的動機付けに基づいてコミュニケーションは進行していくべきです。勿論社会性も必要なので、その外発的動機付けとのバランスに留意すべきでしょう。
結論を言えば、私は「努力をしなければならない」という固定観念に囚われていたことで、いつの間にか外発的なものを目指してしか生きることが出来なくなっていたことが、自分の幸福への足枷になっていたのです。
どうすれば良いのか
じゃあ、どうすれば良いのか。取り合えず、一旦「努力が一番」の原則を手放しましょう。私は、自分の好きなものに対して貪欲になるような姿勢を見せるべきです。行きたい場所があれば直ぐに旅行に行って写真を撮る、会いたい人がいれば直ぐに会って楽しく会話する。そういうことに罪悪感や引け目を感じずに、そこが人生の一番であるということを、自分に許しても良いのではないでしょうか?
自分の好きなものを選び取り、好きなものに囲まれて生活する。そういう「当たり前の幸福」を、私は私に対して真に許してなかった。もっと好きなものに正直になっても良いのではないか。結局、そういった我儘とも思える行為が自分を成長させるし、自分軸となり、生きていく上での支えとなっていくのです。
努力も、それ自体が目的となるのではなく、努力して達成した後に構えている未来を意識すべきです。私は、外発的動機付けを意識しすぎた結果、「幸福になる」という目的に対して、手段と目的をはき違えていました。
未来をどう幸福で埋め尽くしていくか。それを考えるのは十分に高度なことだし、十分に人生の目的たり得ます。
社会的な要請や、どうにもならないことは存在するので、「努力を楽しむ」「与えられたものを好きになる」姿勢は何処かに残しておくのが良いとは考えます。しかし、最終的な目的が現在未来の永続的な幸福であり、そこに日々向かっていることは忘れてはなりません。
おわりに
今回は、自分の内発的動機付けを大切にしたいというブログを書きました。しかし、私は慣れておらず、主体的に選び取ることの方法を頭でも心でもまだあまり理解していません。「信念の醸成」にも関係してくると私は述べましたが、これとの関係性もフワッとしたものでしかありません。日々の中で意識的に、自分の好きなものに基づいて選択するような行動を増やしていくことで、自分の見識を深めていきたいと考えています。
また何か気づきがあればこのシリーズを書きます。それでは!
ランダム投稿&定時に日数をカウントダウンしてくれるDiscord botの作り方解説
function morning() { const discordWebHookURL = "ここにdiscord botのWebhookを取ってくる"; // 試験名 var examName = '第58回気象予報士試験'; // 試験日 var examDate = new Date('2022/08/21 23:59:59'); // 本日日付 var today = new Date(); // 試験日までの日数を取得 days = Math.floor((examDate - today) / (24*60*60*1000)); today = Utilities.formatDate(today,"JST", "yyyy/MM/dd"); // メッセージを送信する if(days >= 0){ // シートデータ取得 var id = "参照する"; var spreadsheet = SpreadsheetApp.openById(id); var sheet = spreadsheet.getSheetByName('シート1'); var lastRow = sheet.getLastRow(); //2行目~最終行の間で、ランダムな行番号を算出する var row = Math.ceil(Math.random() * (lastRow-1)) + 1; var question = sheet.getRange(row, 2).getValue(); var answer = sheet.getRange(row, 3).getValue(); var citation = sheet.getRange(row, 4).getValue(); if(citation == ""){ title = '今日の1回目の正誤問題はこれ!' }else{ title = '今日の1回目の正誤問題は __' + citation + '__ から!' } const message = { "content": 'おはよう!\n' + examName + 'まであと**' + days + '**日!', // チャット本文 "tts": false, // ロボットによる読み上げ機能を無効化 "embeds": [ { "title": title, "description": question +'\nこれは〇か✕か?\n\n' +'解答は '+ '|| '+answer+' ||'+' だよ!\n(↑クリックまたはタップしてみてね!)', "color": 16753920, } ] } const param = { "method": "POST", "headers": { 'Content-type': "application/json" }, "payload": JSON.stringify(message) } UrlFetchApp.fetch(discordWebHookURL, param); } }
はじめに
こんにちは、hiroです。今日は、Discordで作ったランダム投稿&定時に日数をカウントダウンをしてくれるDiscord bot(通称はれるん問題出題bot)の作り方と、プログラム全容を解説していきたいと思います。上に貼ったのがプログラムの全容です。意外と少ない???順を追って解説していきます。
作り方解説
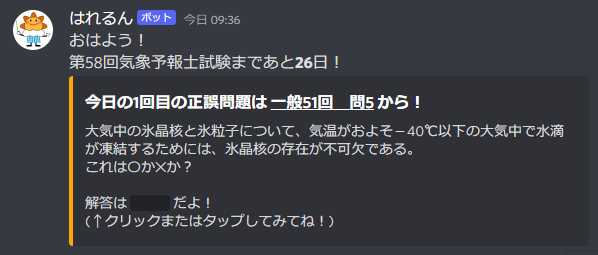
完成品は上のようになっています。やっていることとしては、
というものです。それぞれの機能について、順を追って実装方法について解説していきたいと思います。
1.毎日定時で投稿する機能の実装
毎日定時で投稿するという機能を達成するために、Google Apps Script(通称GAS)というGoogle スプレッドシート付属の機能を使っています。

スプレッドシートからGASへ飛ぶと、以下のような画面が出てきます。
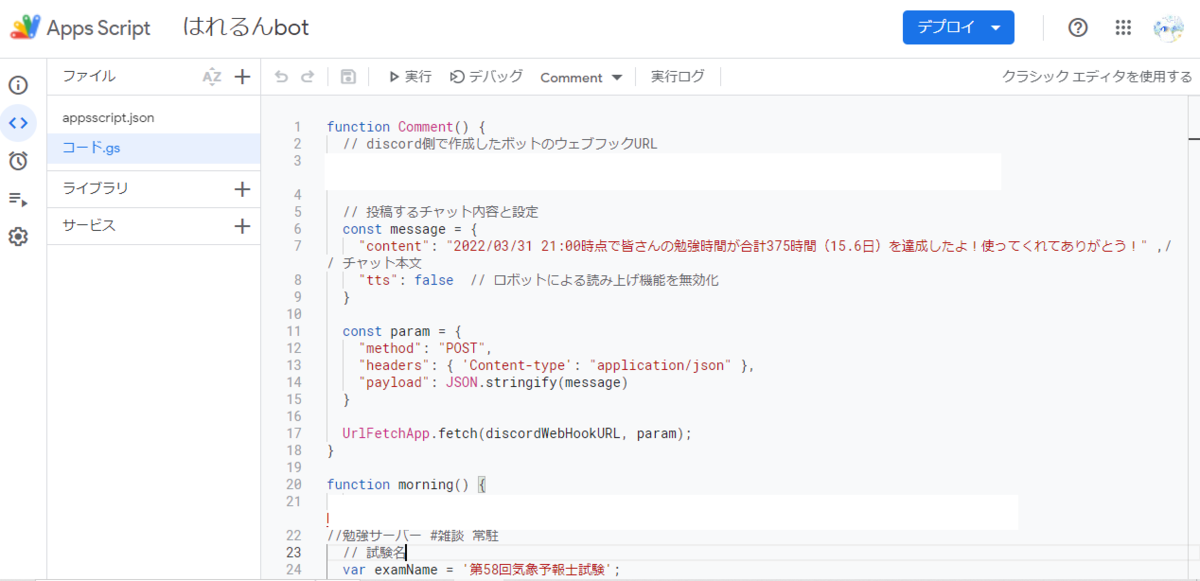
ここに実行したいプログラムを書いて「実行」ボタンを押すと、プログラムを動かしてくれる仕組みになっています。GASの言語はjavascriptですので、pythonを書いたことがある方なら同じインタプリタ言語として比較的スムーズに書けるんじゃないかと思います。

GASの特色として、定時投稿をしやすいのでこのbotではGASを使っています。というのも、標準機能として左側タブから「トリガー」ボタンを押して上のような画面に飛び、多少の設定するだけで、自動で決まった時間に指定のプログラムを実行してくれるという優れものなんです。GAS以外のプラットフォームを使おうと思うと、サーバーを用意したり、定時投稿するプログラムを別途書いたりする必要があるので、今回のようなランダム投稿&日数カウントダウンの機能を持ったbotを動かしたい場合、GASを使用するのをお勧めします。
上の画像では、朝、夕方、夜、の1日に3回問題投稿がされるようトリガーを設定しています。朝しかカウントダウンをしない設定にしている為、プログラムを朝用、夕方用、夜用、と別途用意してそれぞれのプログラムを指定の時間に実行されるように設定しています。
GASとDiscord、スプレッドシートを紐づける
ここからは、GASの中のプログラム内のコードについても解説していきます。まずは、コードを書く際、このGASが指定のDiscordに投稿されるよう設定しなければなりません。また、問題を出題する際、スプレッドシートに記載されている内容からランダムに取ってくる仕様にしたいので、GASが問題スプレッドシートにアクセスできるようにする必要があります。そこの解説についてです。
Diccord Webhook URLの取得
qiita.com
詳細については上のURLを参考にしてください。DIscordの設定画面からWebhook URLを取得します。
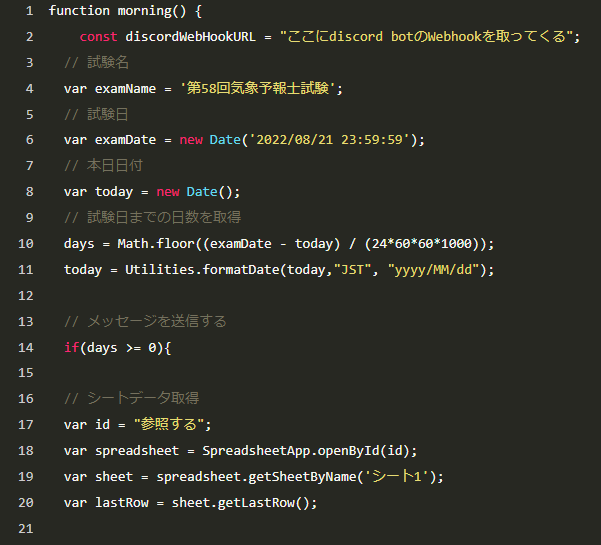
2.気象予報士試験までの日数をカウントする機能の実装
ここで、コードの初めの部分が出てきたので、ここのプログラムの解説について行いたいと思います。この部分は、プログラムの核となる部分を書くための下ごしらえパートとなっています。この部分で、気象予報士試験までの日数を計算しています。それでは見ていきましょう。
1行目では「morning」という関数を定義しています。実行するときは、GASの「実行する関数を選択」ボタンから「morning」を選択してください。
4行目、6行目、8行目ではそれぞれ試験名、試験日、本日の日付を定義しています。
10行目ではMath.floor関数を使い、試験日と本日の日付の差分(ミリセカンドで出力される)を日付に直し、小数点以下は切り捨てることで試験までの日数を「days」に格納しています。
11行目では、本日の日付のフォーマットを日本時間の「西暦/月/日」の形式に変換しています。
14行目では、if関数を用いてdaysが0以上、すなわち気象予報士試験に到達するまでの期間に、それ以下のプログラムを実行するよう定めています。
17,18,19行目では指定のスプレッドシートの「シート1」を参照するように言っています。以下、「sheet」の後にコマンドを入力することでこのシートを操作することが出来るようになっています。
ここまでが下ごしらえパートです!10行目で、気象予報士試験までの日数カウントダウン部分が計算されました。
3.気象予報士試験の問題をランダムに投稿する機能の実装


それでは、20行目以降のプログラムの根幹に関わる部分の解説を進めます。ここで問題をランダムに投稿する部分のコードが書かれています。前から順番に解説していきましょう。
20行目では、スプレッドシートの書き込みがある部分(問題が書かれている部分)の最終行を「lastrow」として保存しています。
23行目では、Math.randomで0~1の中で乱数を取得し、全行となる「lastlow -1」を掛け合わせ、Math.ceilでその値を切り上げた後、1を足しています。これにより、2行目から最終行目までの無作為な行数について抽出しています。これを「row」として保存しています。

スプレッドシート内では、上図のようにB列に問題、C列に〇か✕の答え、D列に引用元の試験回を記録しています。25,26,27行目では、「question」「answer」「citation」に、23行目でランダムに選んだ行のB列、C列、D列の値を格納しています。
28行目~32行目では、もし引用元があればそれを示し、無ければそれを含まないような「title」を格納しています。「title」は「message」としてDiscordに投稿する際の重要な引数となっています。
それでは、以下はDiscordに投稿する際の内容です。
34行目で、以下の行で「message」を定義すると宣言しています。メッセージは、「おはよう!試験まであと○○日!」という内容になっています。○○のところには10行目で計算した日数が入ります。また、Discordの中でロボットが読み上げる機能を無効化しています。それが35行目、36行目の内容です。
37行目~43行目では「embeds」を定義しています。これは、Discord特有の投稿装飾機能です。

太字部分が先ほど定義した「title」、細字部分が「discription」、「color」は左側の装飾色で、カラーコードで指定しています。DIscordの規則として、「**」で囲むとアンダーライン、「||」で囲むとブラインド(クリック又はタップで表示)、「\n」で改行となっています。
46行目~50行目は投稿に関わる形式を指定している部分です。「param」に「message」の形式を格納しています。
52行目で、指定のDiscordチャンネルに「param」を実際に投稿しています。
プログラムは以上のようになっています。
このプログラムを活用すると…


このはれるん問題出題botのプログラムを利用して、私は2つの派生botを作りました。
1つ目は、気象庁のHPから予め重要な部分を抽出しておいて無作為にHPへのリンクを教えてくれる「気象庁bot」です。私は、気象予報士専門試験対策の為に、気象庁のHPを毎日読めるようなbotがあれば良いな~と思いこのbotを作成しました。春ちゃんが季節の挨拶と共に気象庁HPへの案内をしてくれます。
2つ目は、試験までの日数を毎日カウントダウンしてくれる「秘書bot」です。「計画的に頑張ってくださいね!」という励ましとともに、推しキャラが受ける予定である試験までのカウントダウンを毎日早朝に行ってくれます。毎日、私はこれを見て「今日も頑張ろう!」という気持ちで出勤しています。
使い方は色々あると思います。皆さんそれぞれに自分に役立つDIscord botを作成されては如何でしょうか?